
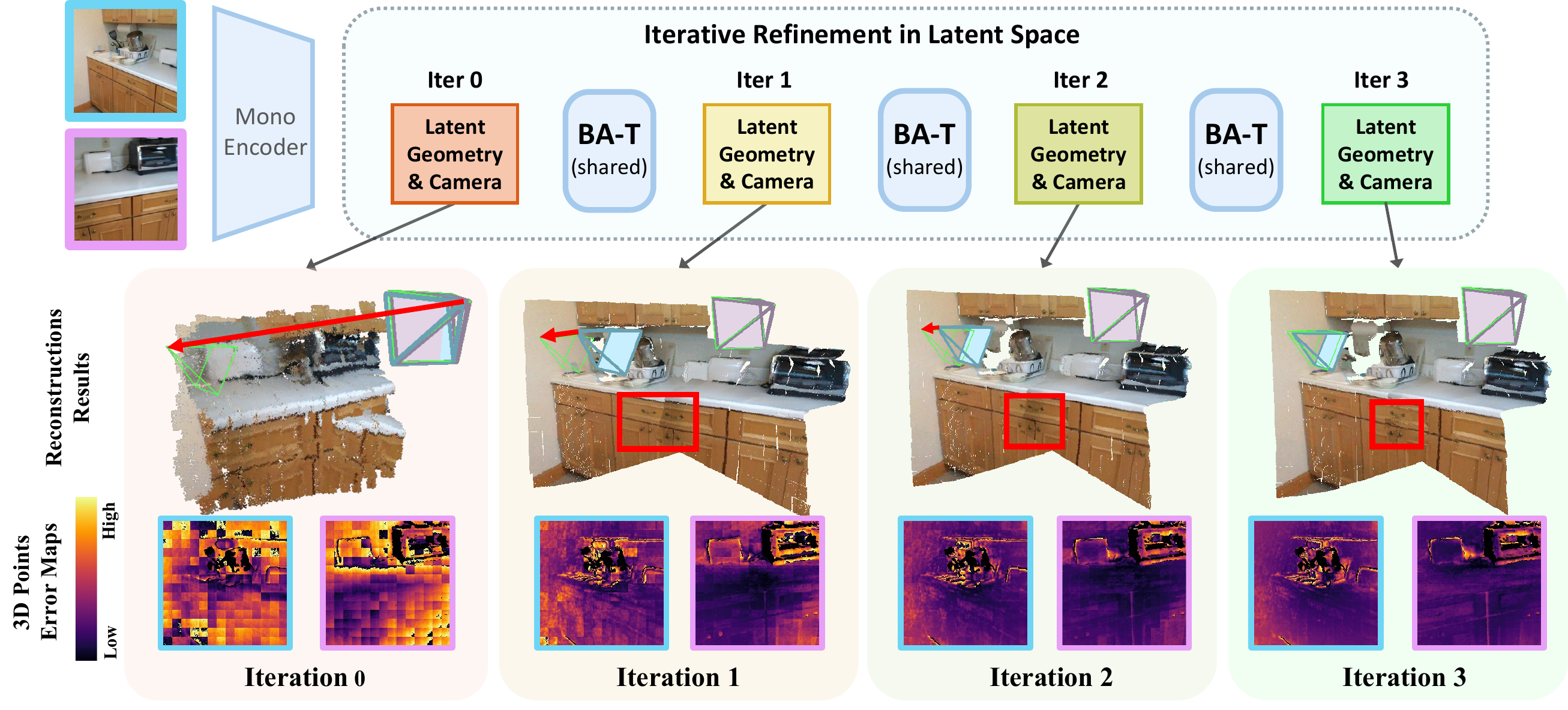
BA-T is an iterative Transformer for two-view bundle adjustment that implements BA-style structured updates as a single lightweight, repeatable layer in implicit token space. Rather than relying on deep attention stacks, it refines poses and local geometry from latent residuals across iterations, achieving stronger cross-view consistency and matching or surpassing much larger models while using only 16% of their decoder parameters.

Flow4R is a feed-forward framework for dynamic 4D reconstruction and tracking from unposed image pairs. By modeling camera-space scene flow as a unified representation of geometry, object motion, and camera motion, it predicts 3D position and bidirectional motion in a single forward pass without explicit pose regression or bundle adjustment, achieving state-of-the-art accuracy and temporal consistency.
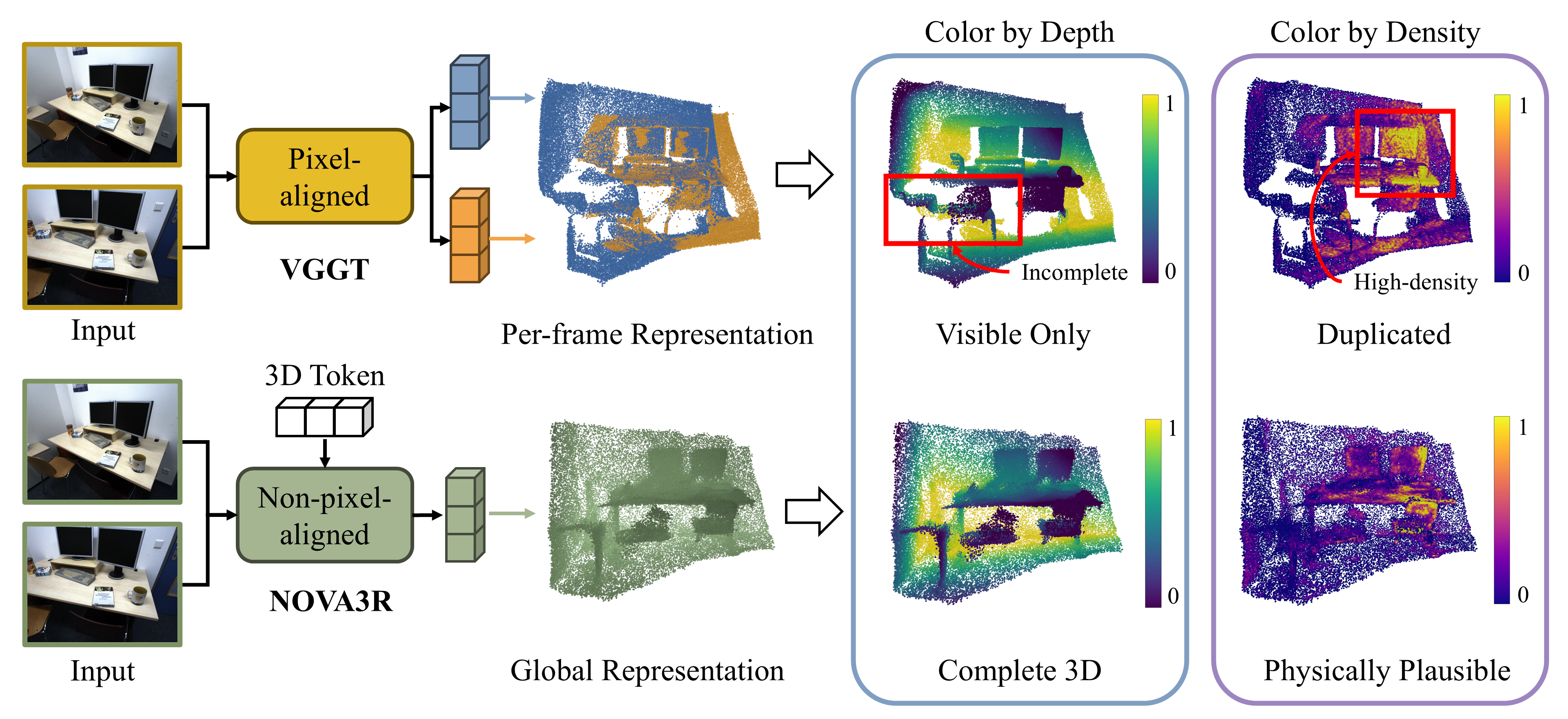
NOVA3R is a feed-forward method for non-pixel-aligned 3D reconstruction from unposed images that learns a global, view-agnostic scene representation via scene tokens and a diffusion-based 3D decoder, enabling complete and physically plausible geometry and outperforming state of the art in accuracy and completeness.
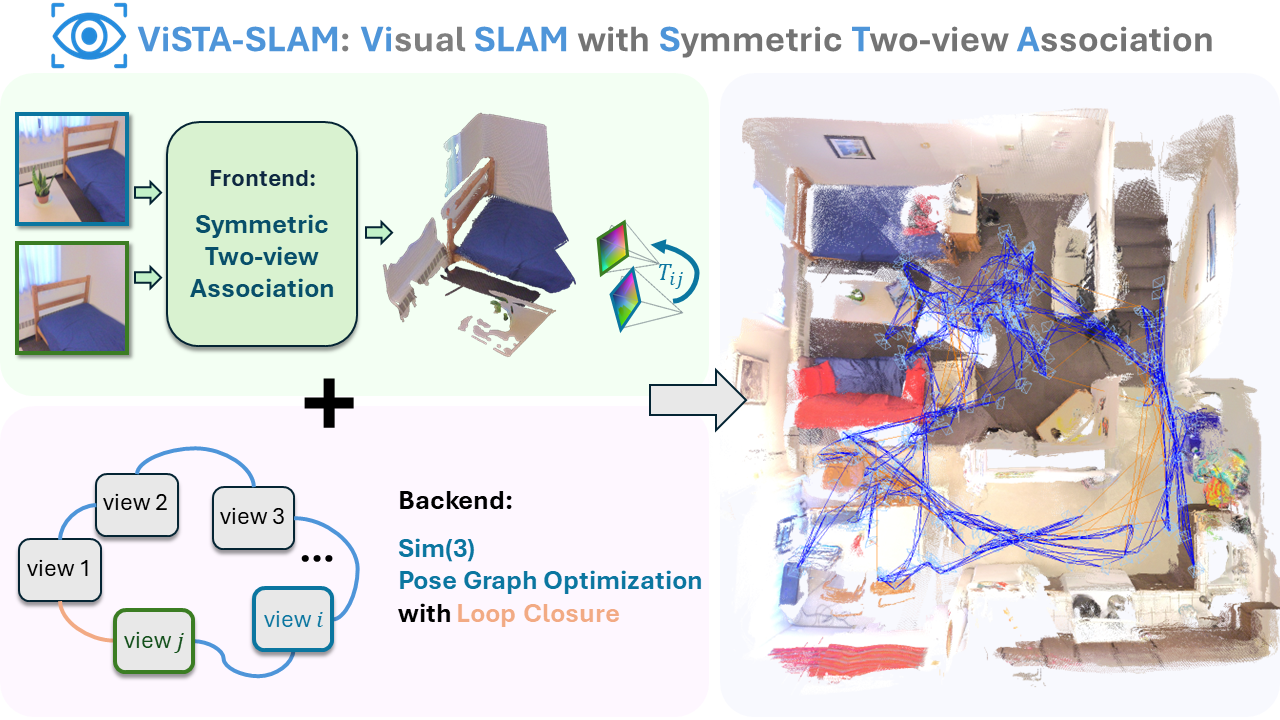
ViSTA-SLAM is a real-time monocular dense SLAM pipeline that combines a Symmetric Two-view Association (STA) frontend with Sim(3) pose graph optimization and loop closure, enabling accurate camera trajectories and high-quality 3D scene reconstruction from RGB inputs.
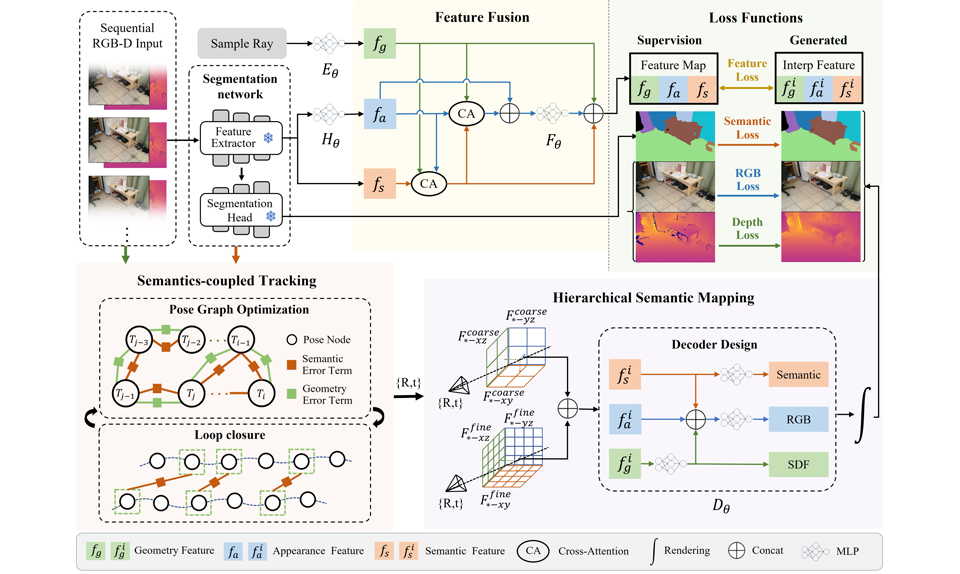
SNI-SLAM++ is a tightly coupled semantic SLAM system that achieves robust tracking and dense semantic mapping through hierarchical semantic encoding, cross-attention feature fusion, and a semantics-coupled tracking framework.
A method for consistent dynamic scene reconstruction via motion decoupling, bundle adjustment, and global refinement.

We use a keyframe based frame to frame tracker based on dense optical flow connected to a pose graph for global consistency. For dense mapping, we resort to a 3DGS representation, suitable for extracting both dense geometry and rendering from.

1. A monocular SLAM pipeline with deformable neural point cloud scene representation.
2. Novel DSPO layer for BA, which can jointly optimize depth map, depth scale, and camera pose.
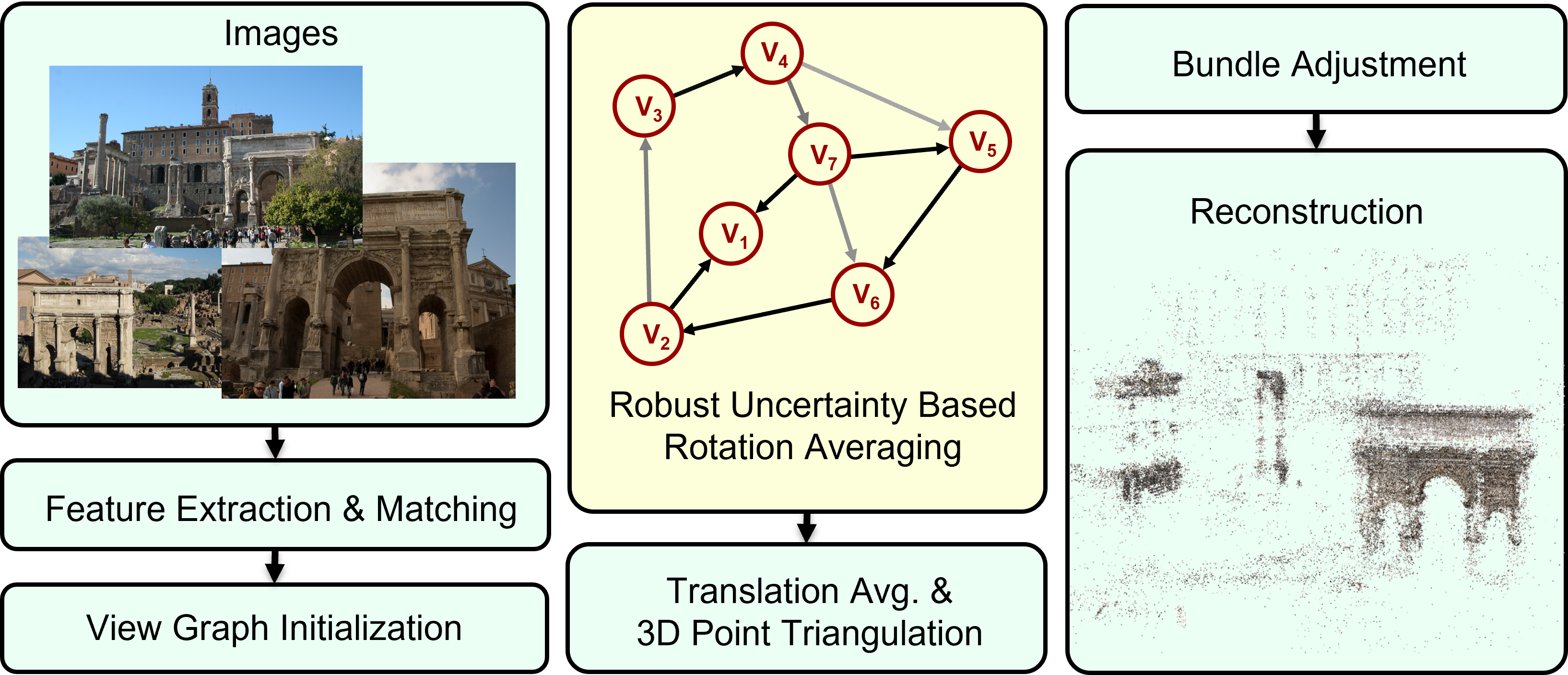
1. Better model the underlying noise distributions by directly propagating the uncertainty from the point correspondences into the rotation averaging.
2. Integrate a variant of the MAGSAC++ loss into the rotation averaging, instead of using the classical robust losses.